The continuous Hierarchical Gaussian Filter#
![]()
In this notebook, we illustrate applications of the standard two-level and three-level Hierarchical Gaussian Filters (HGF) for continuous inputs. This class of models slightly differs from the previous binary example as input nodes here are not restricted to boolean variables but accept any observations on a continuous domain. Fitting continuous data allows using the HGF with any time series, which can find several applications in neuroscience (see for example the case study on physiological modelling using the Hierarchical Gaussian Filter Example 1: Bayesian filtering of cardiac volatility). The continuous HGF is built on to of the following probabilistic networks:

Fig. 7 The two-level and three-level Hierarchical Gaussian Filter for continuous inputs. All nodes are continuous state nodes. The first node (\(x_0\)) can observe new values.#
Here, we will use the continuous HGF to predict the exchange rate of the US Dollar to the Swiss Franc during much of 2010 and 2011 (we use this time series as it is a classical example in the Matlab toolbox).
timeserie = load_data("continuous")
Fitting the continuous HGF with fixed parameters#
The two-level continuous Hierarchical Gaussian Filter#
Create the model#
Note
The default response function for a continuous HGF is the sum of the Gaussian surprise at the first level. In other words, at each time point the model try to update its hierarchy to minimize the discrepancy between the expected and real next observation in the continuous domain.
two_levels_continuous_hgf = (
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4, mean=timeserie[0], tonic_volatility=-13.0, value_children=0
)
.add_nodes(precision=1e1, tonic_volatility=-2.0, volatility_children=1)
)
This function creates an instance of an HGF model automatically parametrized for a two-level continuous structure, so we do not have to worry about creating the node structure ourselves. This class also embed function to add new observations and plots results of network structure. We can visualize the node structure using the pyhgf.plots.plot_network() function that will draw the nodes Graphviz.
two_levels_continuous_hgf.plot_network()

Add data#
# Provide new observations
two_levels_continuous_hgf = two_levels_continuous_hgf.input_data(input_data=timeserie)
Plot trajectories#
A Hierarchical Gaussian Filter parametrized with the standard Gaussian surprise as a response function will act as a Bayesian filter. By presenting new continuous observations and running the update equation forward, we can observe the trajectories of the parameters of the node that are adapting to the trajectory and volatility of the input time series (i.e. the mean \(\mu\) and the precision \(\pi\)). The plot_trajectories function automatically extracts the relevant parameters given the model structure and plots their evolution together with the input data.
two_levels_continuous_hgf.plot_trajectories(show_total_surprise=True);
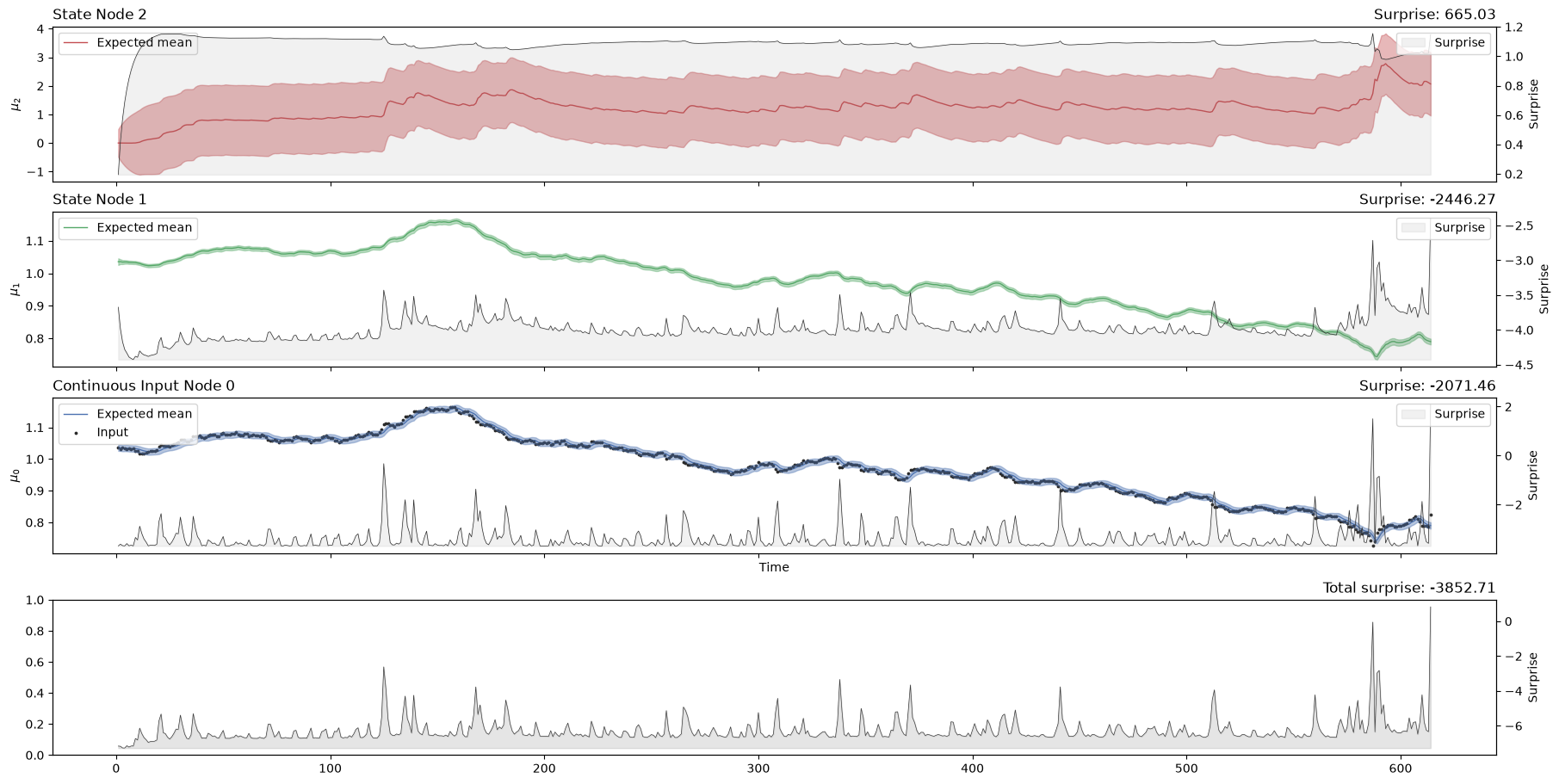
Looking at the volatility level (i.e. the orange line in the first panel), we see that there are two salient events in our time series where volatility shoots up. The first was in April 2010 when the currency markets reacted to the news that Greece was effectively broken. This leads to a flight into the US dollar (the grey dots rising very quickly), sending the volatility higher. The second is an accelerating increase in the value of the Swiss Franc in August and September 2011, as the Euro crisis dragged on. The point where the Swiss central bank intervened and put a floor under how far the Euro could fall with respect to the Franc is visible in Franc’s valuation against the Dollar. This surprising intervention shows up as another spike in volatility.
We can see that the surprise will increase when the time series exhibits more unexpected behaviours. The degree to which a given observation is expected will depend on the expected value and volatility in the input node, which is influenced by the values of higher-order nodes. One way to assess model fit is to look at the total Gaussian surprise for each observation. This value can be returned using the pyhgf.model.HGF.surprise() method:
two_levels_continuous_hgf.surprise(
response_function=first_level_gaussian_surprise
).sum()
Array(-2095.9917, dtype=float32)
Note
The surprise returned by a model when presented with new observations is a function of the response model that was used. Different response functions can be added and provided, together with additional parameters in the pyhgf.model.HGF.surprise() method. The surprise is the negative log probability density of the new observations under the model priors:
Plot correlation#
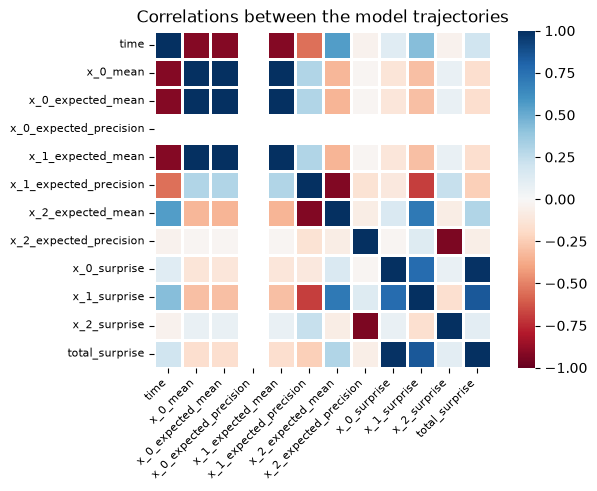
Node parameters that are highly correlated across time are likely to indicate that the model did not learn hierarchical structure in the data but instead overfitted on some components. One way to quickly check the parameters nodes correlation is to use the plot_correlation function embedded in the HGF class.
two_levels_continuous_hgf.plot_correlations();
The three-level continuous Hierarchical Gaussian Filter#
Create the model#
The three-level HGF can add a meta-volatility layer to the model. This can be useful if we suspect that the volatility of the time series is not stable across time and we would like our model to learn it. Here, we create a new pyhgf.model.HGF instance, setting the number of levels to 3. Note that we are extending the size of the dictionaries accordingly.
three_levels_continuous_hgf = (
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4, mean=timeserie[0], tonic_volatility=-13.0, value_children=0
)
.add_nodes(tonic_volatility=-2.0, volatility_children=1)
.add_nodes(tonic_volatility=-2.0, volatility_children=2)
)
The node structure now includes a volatility parent at the third level.
three_levels_continuous_hgf.plot_network()

Add data#
three_levels_continuous_hgf = three_levels_continuous_hgf.input_data(
input_data=timeserie
)
Plot trajectories#
three_levels_continuous_hgf.plot_trajectories();
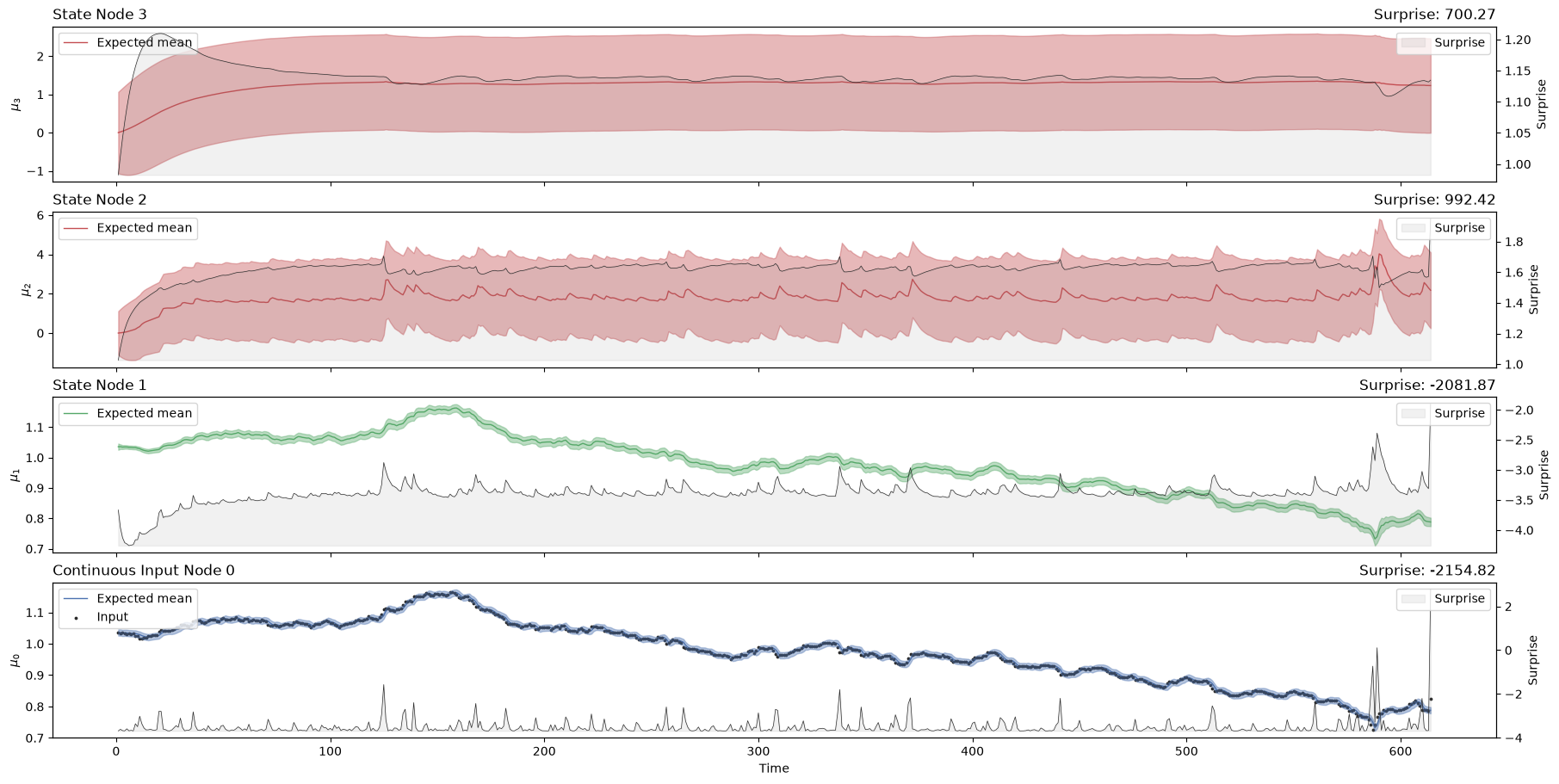
Surprise#
Similarly, we can retrieve the overall Gaussian surprise at the first node for each new observation using the built-in method:
three_levels_continuous_hgf.surprise(
response_function=first_level_gaussian_surprise
).sum()
Array(-2040.8486, dtype=float32)
The overall amount of surprise returned by the three-level HGF is quite similar to what was observed with the two-level model (-964 vs.-965). Because an agent will aim to minimize surprise, it looks like the two-level model is slightly better in this context. However, the surprise will also change as the value for the parameters of the node is optimized beforehand. One important parameter for each node is the tonic volatility (sometimes noted \(\omega\)). This is the tonic part of the variance (the part of the variance in each node that is not affected by the parent node). Here we are going to change the tonic volatility at the second level to see if it can help to minimize surprise:
# create an alternative model with different omega values
# the input time series is passed in the same call
three_levels_continuous_hgf_bis = (
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4, mean=timeserie[0], tonic_volatility=-13.0, value_children=0
)
.add_nodes(tonic_volatility=-1.0, volatility_children=1)
.add_nodes(tonic_volatility=-2.0, volatility_children=2)
).input_data(input_data=timeserie)
three_levels_continuous_hgf_bis.plot_trajectories();
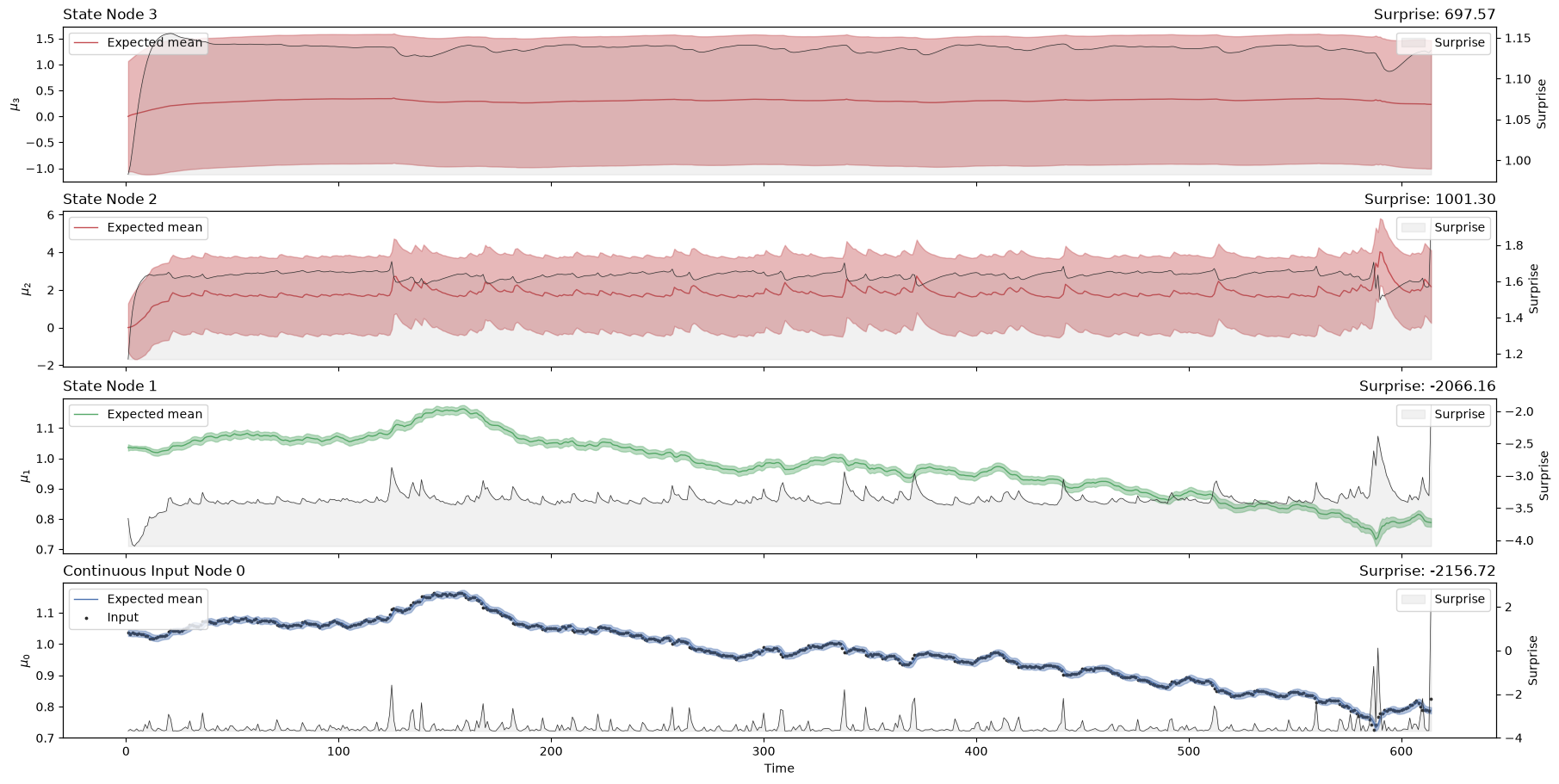
three_levels_continuous_hgf_bis.surprise(
response_function=first_level_gaussian_surprise
).sum()
Array(-2032.2324, dtype=float32)
Now we are getting a global surprise of -828 with the new model, as compared to a global surprise of -910 before. It looks like the \(\omega\) value at the second level can play an important role in minimizing surprise for this kind of time series. But how can we decide on which value to choose? Doing this by trial and error would be a bit tedious. Instead, we can use dedicated Bayesian methods that will infer the values of \(\omega\) that minimize the surprise (i.e. that maximize the likelihood of the new observations given parameter priors).
Learning parameters with MCMC sampling#
In the previous section, we assumed we knew the parameters of the HGF models beforehand. This can give us information on how an agent using these values would have behaved when presented with these inputs. We can also adopt a different perspective and consider that we want to learn these parameters from the data, and then ask what would be the best parameter values for an agent to minimize surprises when presented with this data. Here, we are going to set priors over some parameters and use Hamiltonian Monte Carlo methods (NUTS) to sample their probability density.
Because the HGF classes are built on the top of JAX, they are natively differentiable and compatible with optimisation libraries. Here, we use PyMC to perform MCMC sampling. PyMC can use any log probability function (here the negative surprise of the model) as a building block for a new distribution by wrapping it in its underlying tensor library Aesara, now PyTensor. pyhgf includes a PyMC-compatible distribution that can do this automaticallypyhgf.distribution.HGFDistribution.
Two-level model#
Creating the model#
Note
We create a log-probability function that wraps the previous steps, and 1) create a network with the relevant parameters, 2) provide inputs and run the model forward, and 3) return the negative surprise. We use the first level Gaussian surprise (i.e., the sum of the Gaussian surprises at each new observation) as the response function.
@wrap_jax
def two_level_logp(tonic_volatility, tonic_volatility_2):
"""Compute the log-probability of the two-level HGF."""
return (
-(
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4,
mean=timeserie[0],
tonic_volatility=tonic_volatility,
value_children=0,
)
.add_nodes(tonic_volatility=tonic_volatility_2, volatility_children=1)
)
.input_data(input_data=timeserie)
.surprise(response_function=first_level_gaussian_surprise)
.sum()
)
This log probability function can then be embedded in a PyMC model using the same API. Here, we are going to optimize omega_1. The other parameters are fixed.
Note
The data has been passed to the distribution in the cell above when the function is created.
with pm.Model() as two_level_hgf:
# Set a prior over the evolution rate at the first level.
tonic_volatility = pm.Normal("tonic_volatility", -10, 5.0)
tonic_volatility_2 = pm.Normal("tonic_volatility_2", 0.0, 5.0)
# Call the pre-parametrized HGF distribution here.
# All parameters are set to their default value except omega_1, omega_2 and mu_1.
pm.Potential(
"hgf_loglike",
two_level_logp(
tonic_volatility=tonic_volatility,
tonic_volatility_2=tonic_volatility_2,
),
)
/home/runner/work/pyhgf/pyhgf/.venv/lib/python3.12/site-packages/pytensor/link/jax/ops.py:403: UserWarning: Explicitly requested dtype float64 requested in ones is not available, and will be truncated to dtype float32. To enable more dtypes, set the jax_enable_x64 configuration option or the JAX_ENABLE_X64 shell environment variable. See https://github.com/google/jax#current-gotchas for more.
jnp.ones(shape, dtype=variable.type.dtype)
Note
The \(\omega\) parameters are real numbers that are defined from -\(\infty\) to +\(\infty\). However, as learning rates are expressed in log spaces, values higher than 2 are extremely unlikely and could create aberrant fits to the data. Therefore, here we are using a prior that is centred on more reasonable values.
Visualizing the model#
pm.model_to_graphviz(two_level_hgf)

Sampling#
with two_level_hgf:
two_level_hgf_idata = pm.sample(chains=2, cores=1, backend="jax")
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [tonic_volatility, tonic_volatility_2]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 16 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
az.plot_trace_dist(two_level_hgf_idata);
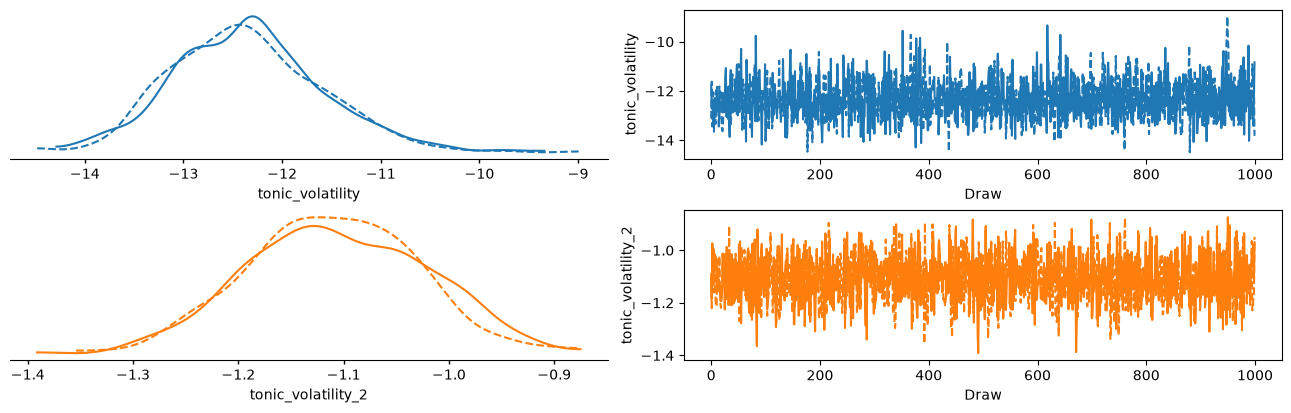
Using the learned parameters#
We can see from the density distributions that the most probable values for \(\omega_{1}\) are found around -7. To get an idea of the belief trajectories that are implied by such parameters, we can fit the model again using the most likely value directly from the sample:
tonic_volatility = az.summary(two_level_hgf_idata)["mean"].astype(float)[
"tonic_volatility"
]
tonic_volatility_2 = az.summary(two_level_hgf_idata)["mean"].astype(float)[
"tonic_volatility_2"
]
hgf_mcmc = (
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4,
mean=timeserie[0],
tonic_volatility=tonic_volatility,
value_children=0,
)
.add_nodes(tonic_volatility=tonic_volatility_2, volatility_children=1)
).input_data(input_data=timeserie)
hgf_mcmc.plot_trajectories();
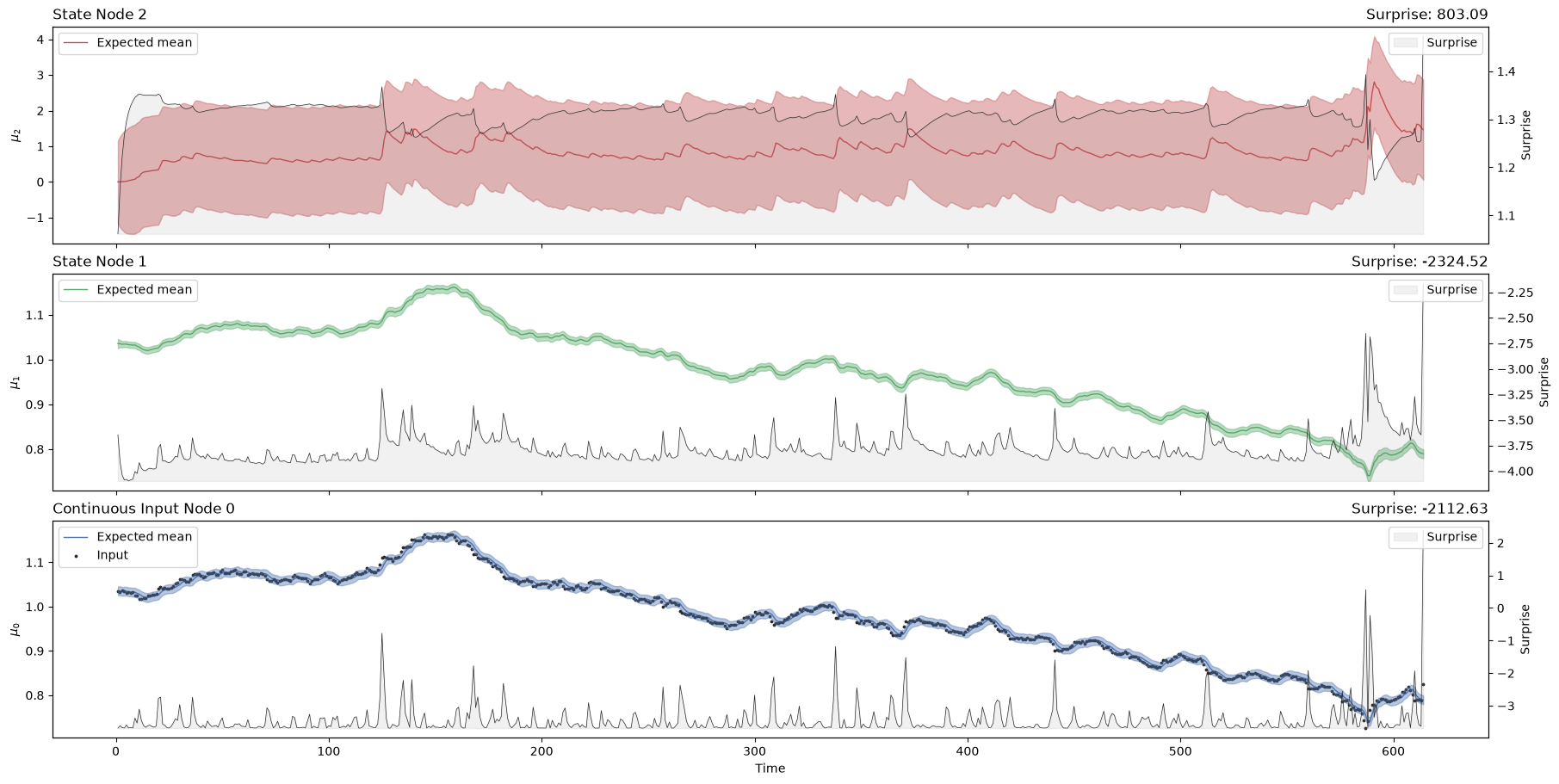
hgf_mcmc.surprise(response_function=first_level_gaussian_surprise).sum()
Array(-2161.1357235, dtype=float64)
Three-level model#
Creating the model#
@wrap_jax
def three_level_logp(tonic_volatility, tonic_volatility_2, tonic_volatility_3):
"""Compute the log-probability of the three-level HGF."""
return (
-(
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4,
mean=timeserie[0],
tonic_volatility=tonic_volatility,
value_children=0,
)
.add_nodes(tonic_volatility=tonic_volatility_2, volatility_children=1)
.add_nodes(tonic_volatility=tonic_volatility_3, volatility_children=2)
)
.input_data(input_data=timeserie)
.surprise(response_function=first_level_gaussian_surprise)
.sum()
)
with pm.Model() as three_level_hgf:
# Set a prior over the evolution rate at the first level.
tonic_volatility = pm.Normal("tonic_volatility", -10, 5.0)
tonic_volatility_2 = pm.Normal("tonic_volatility_2", 0.0, 5.0)
tonic_volatility_3 = pm.Normal("tonic_volatility_3", 0.0, 5.0)
# Call the pre-parametrized HGF distribution here.
# All parameters are set to their default value except omega_1, omega_2, omega_3 and mu_1.
pm.Potential(
"hgf_loglike",
three_level_logp(
tonic_volatility=tonic_volatility,
tonic_volatility_2=tonic_volatility_2,
tonic_volatility_3=tonic_volatility_3,
),
)
Visualizing the model#
pm.model_to_graphviz(three_level_hgf)

Sampling#
with three_level_hgf:
three_level_hgf_idata = pm.sample(chains=2, cores=1, backend="jax")
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [tonic_volatility, tonic_volatility_2, tonic_volatility_3]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 45 seconds.
There were 622 divergences after tuning. Increase `target_accept` or reparameterize.
We recommend running at least 4 chains for robust computation of convergence diagnostics
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
az.plot_trace_dist(three_level_hgf_idata);
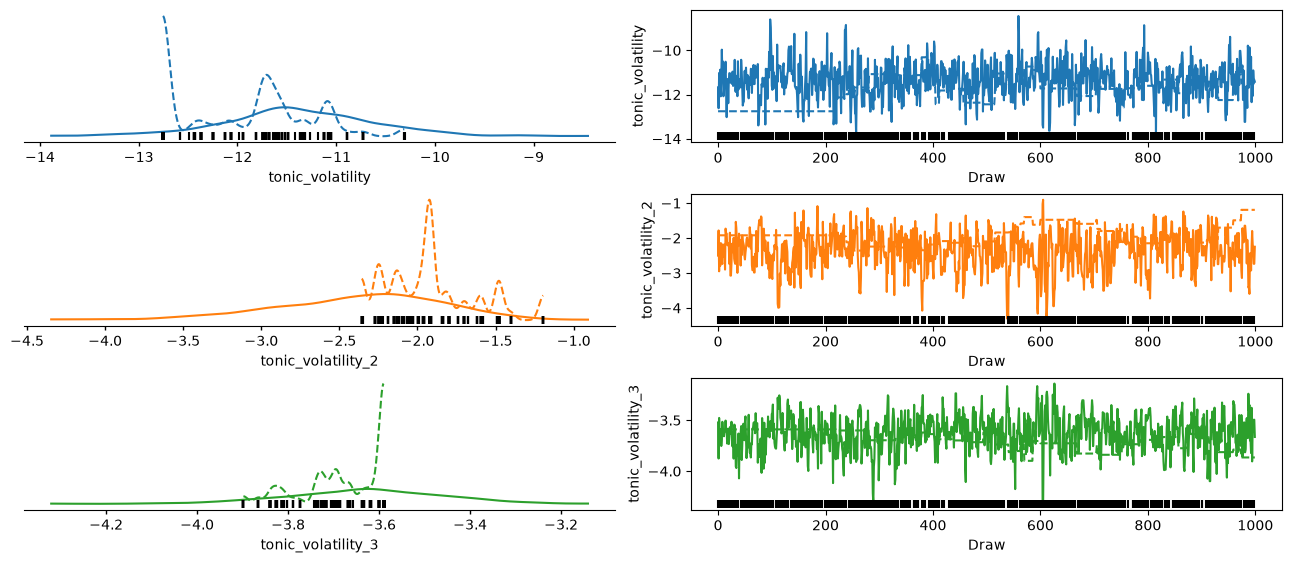
Using the learned parameters#
tonic_volatility = az.summary(three_level_hgf_idata)["mean"].astype(float)[
"tonic_volatility"
]
tonic_volatility_2 = az.summary(three_level_hgf_idata)["mean"].astype(float)[
"tonic_volatility_2"
]
tonic_volatility_3 = az.summary(three_level_hgf_idata)["mean"].astype(float)[
"tonic_volatility_3"
]
hgf_mcmc = (
Network()
.add_nodes(precision=1e4)
.add_nodes(
precision=1e4,
mean=timeserie[0],
tonic_volatility=tonic_volatility,
value_children=0,
)
.add_nodes(tonic_volatility=tonic_volatility_2, volatility_children=1)
.add_nodes(tonic_volatility=tonic_volatility_3, volatility_children=2)
).input_data(input_data=timeserie)
hgf_mcmc.plot_trajectories();
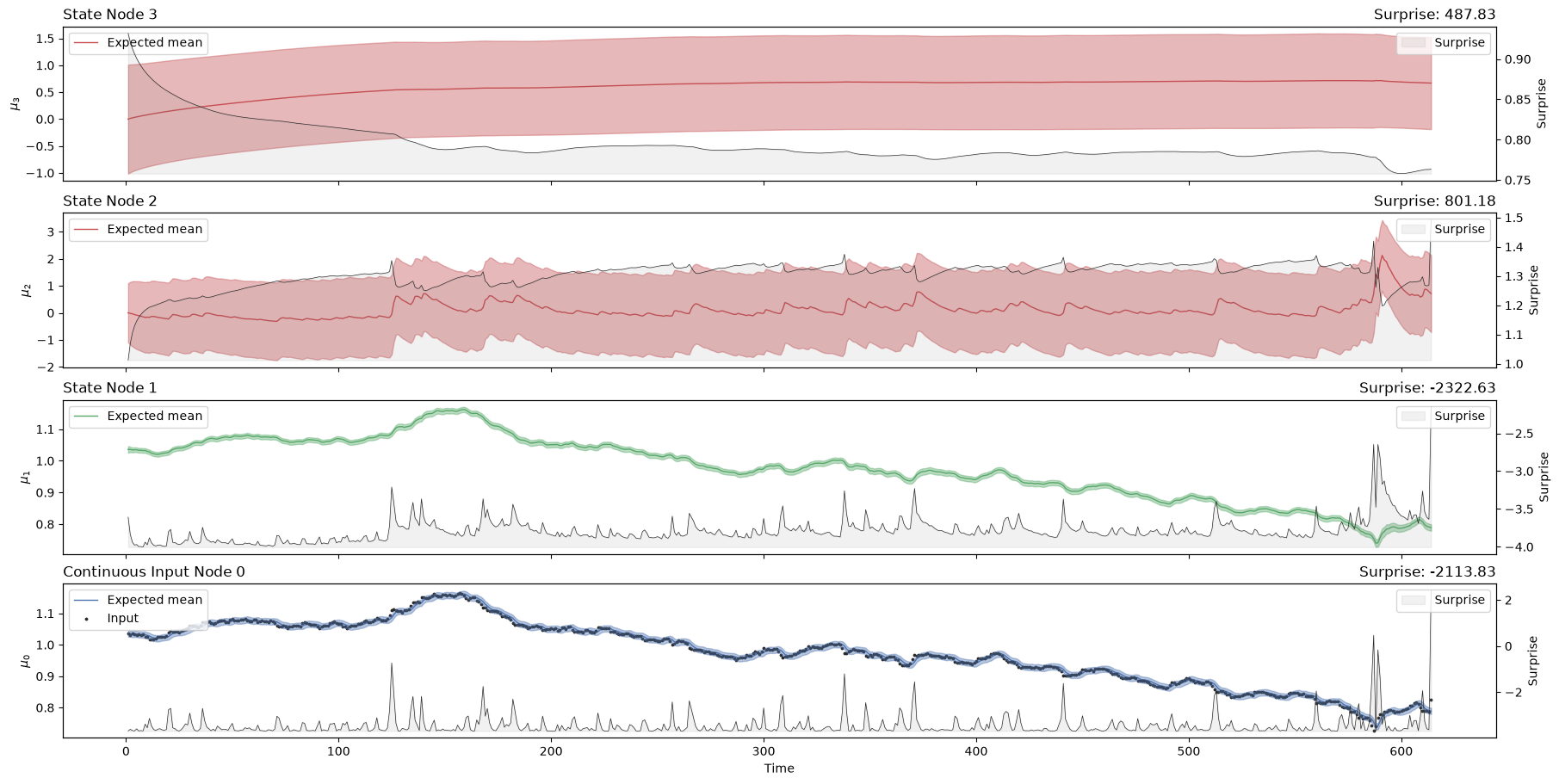
hgf_mcmc.surprise(response_function=first_level_gaussian_surprise).sum()
Array(-2162.49798971, dtype=float64)
System configuration#
%load_ext watermark
%watermark -n -u -v -iv -w -p pyhgf,jax,jaxlib
Last updated: Tue, 16 Jun 2026
Python implementation: CPython
Python version : 3.12.13
IPython version : 9.14.1
pyhgf : 0.3.0
jax : 0.4.31
jaxlib: 0.4.31
IPython : 9.14.1
arviz : 1.2.0
jax : 0.4.31
matplotlib: 3.11.0
pyhgf : 0.3.0
pymc : 6.0.1
pytensor : 3.0.7
Watermark: 2.6.0