Generalised Bayesian Filtering of exponential family distributions#
![]()
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from matplotlib.ticker import MultipleLocator
from scipy.stats import norm, t
from pyhgf.math import MultivariateNormal, Normal, gaussian_predictive_distribution
from pyhgf.model import Network
np.random.seed(123)
plt.rcParams["figure.constrained_layout.use"] = True
In this tutorial, we are interested in online Bayesian filtering when applied to exponential family distributions. Bayesian inference in high-dimensional space can rapidly become intractable, requiring approximation or sampling methods that always remain computationally costly. However exponential family distributions have interesting properties that allow expressing Bayesian updates through a simple closed-form solution over hyperparameters that is common to all family members. This property is well-described for stationary distributions and can extend to non-stationary distributions through the application of a fixed learning rate. But this solution can be further improved by dynamically learning the learning rate itself, which is something that Hierarchical Gaussian Filters are especially good at.
Here, we leverage the approach described in [Mathys and Weber, 2020] to demonstrate that the Hierarchical Gaussian Filter can be generalized to any probability distribution that belongs to the exponential family. In this tutorial we will describe how to filter stationary and non-stationary distributions using a fixed learning rate or by using a predictive coding network on top of sufficient statistics elicited by new observations. This approach has the advantage of being extremely modular and flexible while extending dynamic Bayesian filtering to a whole range of models. This already underpins the The categorical Hierarchical Gaussian Filter, in which case the implied distribution is a Dirichlet distribution.
Theory#
Hint
Exponential family distributions Exponential family distributions are probability distributions which can be written in the form: $\( p(x|\vartheta) = f_x(\vartheta) := h(x) exp(\eta(\vartheta) · t(x) − b(\vartheta)) \)$ where:
\(x\) is a vector-valued observation
\(\vartheta\) is a parameter vector
\(h(x)\) is a normalization constant
\(\eta(\vartheta)\) is the natural parameter vector
\(t(x)\) is the sufficient statistic vector
\(b(\vartheta)\) is a scalar function
It has been shown in [Mathys and Weber, 2020] that, when chosing as prior:
with the variable
as normalization constant, then the posterior is a simple update of the hyperparameters in the form:
Filtering the Sufficient Statistics of a Stationary Distribution#
We start applying this update steps to the estimation of the parameters from a stationary normal distribution.
x = np.arange(-7, 7, 0.01) # x axis
xi, nu = np.array([0, 1 / 8]), 1.0 # initial hyperparameters
xs = np.random.normal(5, 1 / 4, 1000) # input observations
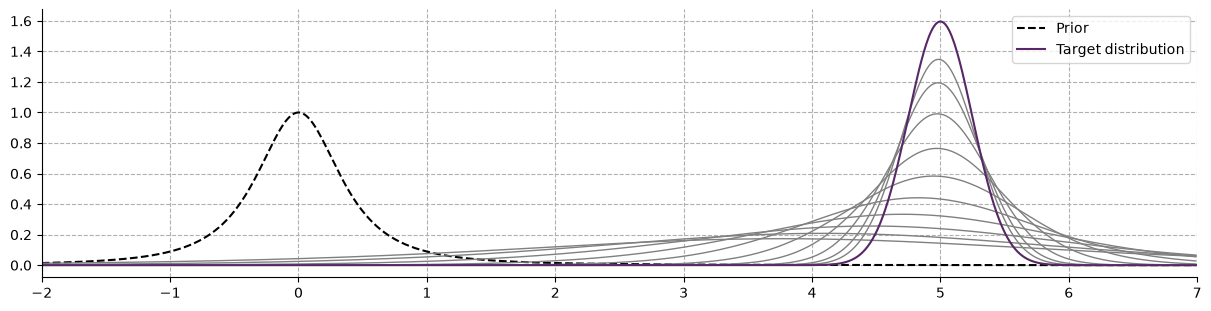
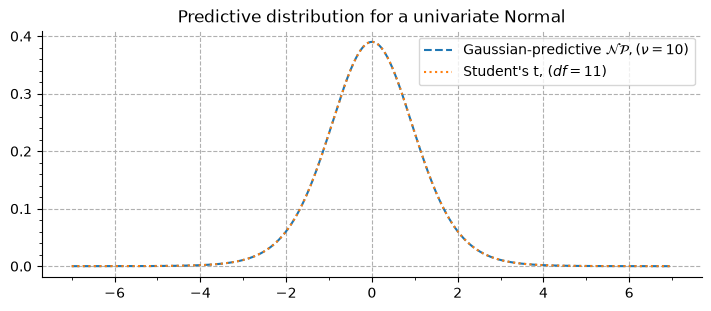
The vizualisation of the predictive distribution over new observations require integrating the joint probability of the prior \(g_{\xi, \nu}(\vartheta)\) and the posterior \(f_x(\vartheta)\). In the case of a univariate normal, the Gaussian-predictive distribution is given by:
When \(\xi = 0, 1\), this corresponds to the Student’s-t distribution with \(\nu + 1\) degrees of freedom, as evidenced here:
Filtering the Sufficient Statistics of a Non-Stationary Distribution#
Real-world applications of Bayesian filtering imply non-stationary distributions, in which cases the agent can no longer rely on distant observation and has to weigh down their evidence proportional to their distance from the current time point. In the current framework, this suggests that \(\nu\), the pseudo-count vector, cannot linearly increase with the number of new observations but has to be limited. The most straightforward way is then to fix it to some values. Here, we start by applying this naive approach to a set of popular distributions, and then for each of them we illustrate how a collection of Hierarchical Gaussian Filters over sufficient statistics can help dynamic inference over the variable \(\nu\) itself.
Gaussian distribution#
Generalised Bayesian Filtering: using a fixed \(\nu\)#
This operation can be achieved using an exponential family state node, using the following parameters:
Setting
kind="ef-state". We also setlearning="generalised-filtering"to explicitly inform the node it should use the general filtering approach (using a fixed \(\nu\))using a 1-dimensional Gaussian distribution by setting
distribution="normal"using
nus=3.0, this parameter will behave as the inverse of a learning rate, informing how much in the past we are looking to update the current sufficient statistics.setting
xis=np.array([0, 1 / 8]), this is our starting point and first guess for the expected sufficient statistics.
Some of these steps were unnecessary, as this is the toolbox’s default behaviour, but we added them here for clarity.
generalised_filter = Network().add_nodes(
kind="ef-state", distribution="normal", nus=3.0, xis=np.array([0, 1 / 8])
)
Note
From sufficient statistics to distribution parameters and backwards
When using a 1-dimensional Gaussian distribution, Setting \(\xi = [0, \frac{1}{8}]\) is equivalent to a mean \(\mu = 0.0\) and a variance \(\sigma^2 = \frac{1}{8}\). You can convert between distribution parameters and expected sufficient statistics using the distribution classes from PyHGF (when implemented):
from pyhgf.math import Normal
# from an observation to sufficient statistics
Normal.sufficient_statistics_from_observations(x=1.5)
Array([1.5 , 2.25], dtype=float32)
# from distribution parameters to sufficient statistics
Normal.sufficient_statistics_from_parameters(mean=0.0, variance=4.0)
Array([0., 4.], dtype=float32)
# from sufficient statistics to distribution parameters
Normal.parameters_from_sufficient_statistics(xis=[0.0, 4.0])
(0.0, 4.0)
The resulting network consists in a single node that encapsulate all computation and do not depends on other nodes. Nodes supporting exponential family distribution can therefore support inputs of various shapes whithout requiring multiple input nodes.
generalised_filter.plot_network()

We then create a time series to filter and pass it to the network using different values for the parameter \(\nu\), representing how much past values should influence the Bayesian update.
x = np.arange(0, 1000) # time points
# create noisy input time series with switching means
y = np.random.normal(0, 1 / 8, 1000)
y[200:400] += 0.5
y[600:800] -= 0.5
generalised_filter.input_data(input_data=y);
means, variances = [], []
nus = [3, 9, 35]
for nu in nus:
# set a new learning rate
generalised_filter.attributes[0]["nus"] = nu
# fit to new data and convert the sufficient statistics into distribution parameters
mean, variance = Normal.parameters_from_sufficient_statistics(
xis=generalised_filter.input_data(input_data=y).node_trajectories[0]["xis"].T
)
# save distribution parameters
means.append(mean)
variances.append(variance)
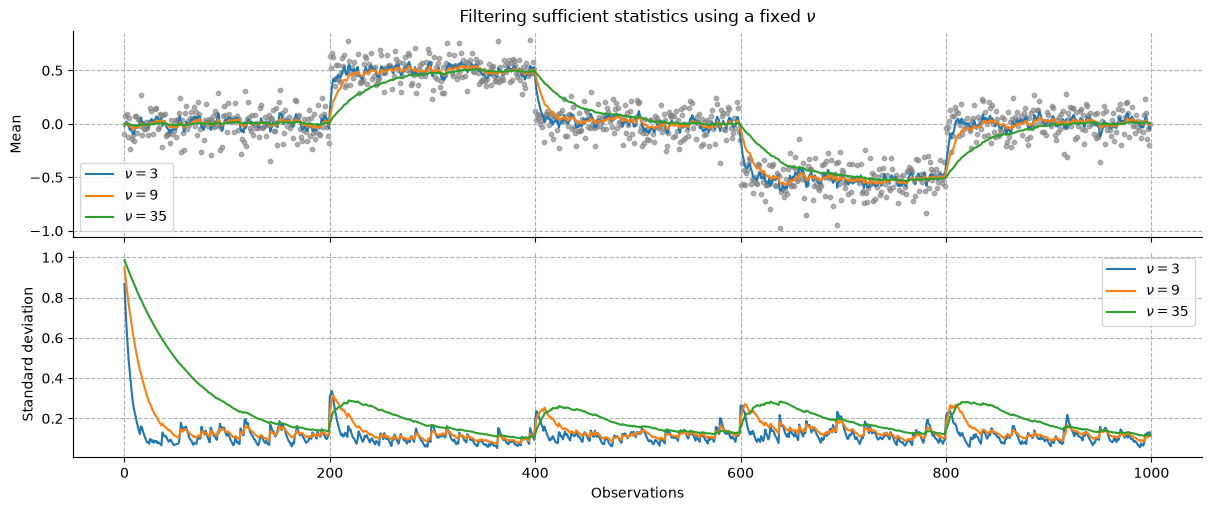
We can see that larger values for \(\nu\) correspond to a lower learning rate, and therefore smoother transition between states.
Using a dynamically adapted \(\nu\) through a collection of Hierarchical Gaussian Filters#
Limiting the number of past observations weighting in the predictive distribution comes with the difficult question of how to choose the correct value for such a parameter. Here, one solution to handle this is to let this parameter vary across time as a function of the volatility of the observations. Large unexpected variations should increase the learning rate, while limited, expected variations should increase the posterior precision. Interestingly, this is the kind of dynamic adaptation that reinforcement learning models are implementing, including the Hierarchical Gaussian Filter in this category. Here, we can derive the implied \(\nu\) from a ratio of prediction and observation differentials such as:
with \(\delta\) the prediction error at time \(k\) and \(\Delta\) the differential of expectations (before and after observing the new value).
univariate_hgf = Network().add_nodes(kind="ef-state", learning="hgf-1")
univariate_hgf.attributes[1]["precision"] = 100.0
univariate_hgf.attributes[4]["precision"] = 100.0
univariate_hgf.plot_network()

univariate_hgf.input_data(input_data=y);
# get the sufficient statistics from the first observation to parametrize the model
mean, variance = jnp.apply_along_axis(
Normal().parameters_from_sufficient_statistics,
1,
univariate_hgf.node_trajectories[0]["xis"],
)
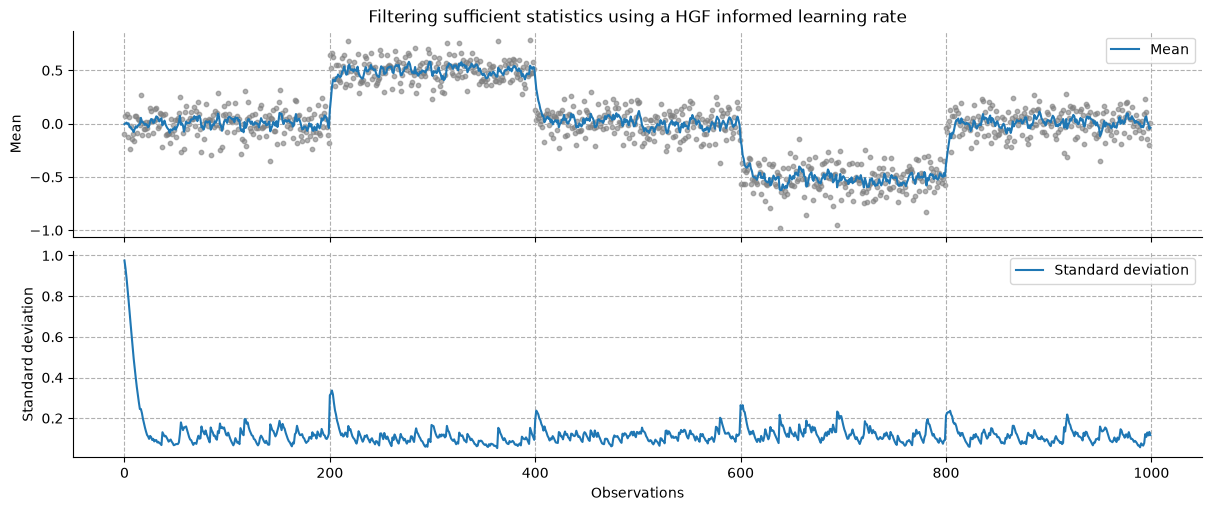
_, axs = plt.subplots(figsize=(12, 5), nrows=2, sharex=True)
axs[0].scatter(x, y, color="grey", alpha=0.6, s=10)
axs[0].plot(x, mean, label="Mean")
axs[0].grid(linestyle="--")
axs[0].set_title(r"Filtering sufficient statistics using a HGF informed learning rate")
axs[0].set_ylabel("Mean")
axs[0].legend()
axs[1].plot(x, jnp.sqrt(variance), label="Standard deviation")
axs[1].grid(linestyle="--")
axs[1].set_xlabel("Observations")
axs[1].set_ylabel("Standard deviation")
axs[1].legend()
sns.despine()
Note
In this model, each sufficient statistic is filtered separately, resulting in an implied learning rate for each of them. While this approach has the advantage of dynamically learning the various components of a distribution (see also how this can be done by value and volatility parents in the case of a continuous input Example 2: Estimating the mean and precision of a time-varying Gaussian distributions), this can result in invalid sufficient statistics (e.g. where the equality \(\xi_1^2 = \xi_2\) does not hold anymore). Here, and in the rest of the examples, we simply average the learning rate to ensure consistent updating of the predictive distribution.
Multivariate Gaussian distribution#
# simulate an ordered spiral data set
N = 1000
theta = np.sort(np.sqrt(np.random.rand(N)) * 5 * np.pi)
r_a = -2 * theta - np.pi
spiral_data = np.array([np.cos(theta) * r_a, np.sin(theta) * r_a]).T
spiral_data += (
np.random.randn(N, 2) * 0.75
+ np.random.randn(N, 2)
* 1.5
* np.tile(np.repeat((0, 1, 0, 1, 0, 1, 0, 1, 0, 1), 100), (2, 1)).T
)
Generalised Bayesian Filtering: using a fixed \(\nu\)#
bivariate_normal = (
Network()
.add_nodes(
kind="ef-state",
nus=8.0,
learning="generalised-filtering",
distribution="multivariate-normal",
dimension=2,
)
.input_data(input_data=spiral_data)
)
# get the sufficient statistics from the first observation to parametrize the model
means, covariances = jnp.apply_along_axis(
MultivariateNormal().parameters_from_sufficient_statistics,
1,
bivariate_normal.node_trajectories[0]["xis"],
dimension=2,
)
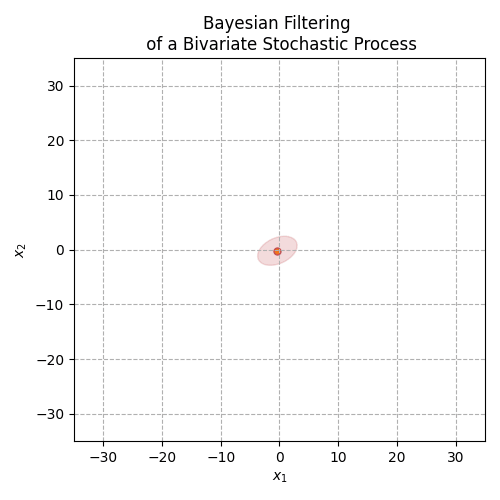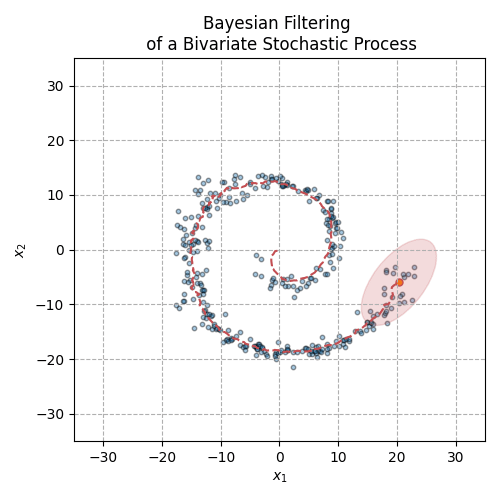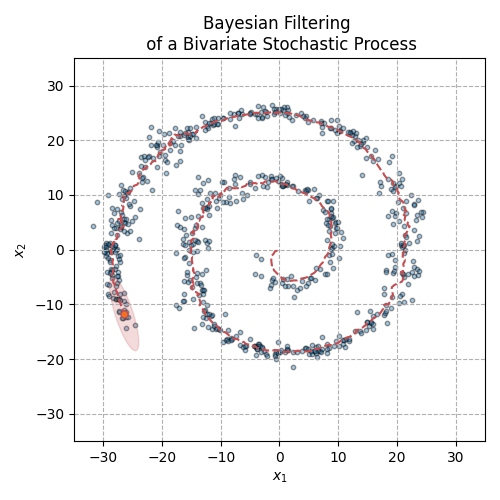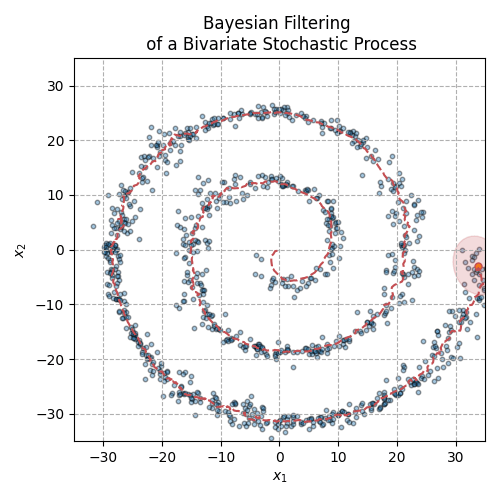
Fig. 3 The animation above displays the mean and covariance tracking of a bivariate normal distribution. The ellipse represents the 95% confidence interval of the covariance matrix. We can see that uncertainty is increasing in noisier sections of the distribution trajectory.#
Note
Code to create this animation 👈
from matplotlib.animation import FuncAnimation
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import chi2
from matplotlib.patches import Ellipse
from pyhgf.model import Network
import jax.numpy as jnp
from pyhgf.math import MultivariateNormal
# simulate an ordered spiral data set
N = 1000
theta = np.sort(np.sqrt(np.random.rand(N)) * 5 * np.pi)
r_a = -2 * theta - np.pi
spiral_data = np.array([np.cos(theta) * r_a, np.sin(theta) * r_a]).T
spiral_data += np.random.randn(N, 2) * .75 + np.random.randn(N, 2) * 1.5 * np.tile(np.repeat((0, 1, 0, 1, 0, 1, 0, 1, 0, 1), 100), (2, 1)).T
bivariate_normal = Network().add_nodes(
kind="ef-state",
nus=8.0,
learning="generalised-filtering",
distribution="multivariate-normal",
dimension=2
).input_data(input_data=spiral_data)
# get the sufficient statistics from the first observation to parametrize the model
means, covariances = jnp.apply_along_axis(
MultivariateNormal().parameters_from_sufficient_statistics, 1, bivariate_normal.node_trajectories[0]["xis"], dimension=2
)
def plot_confidence_intervals(mean, cov, confidence_level=.95, plot=True):
# Chi-squared value for the confidence level
chi2_val = chi2.ppf(confidence_level, df=2)
scaling_factor = np.sqrt(chi2_val)
# Eigenvalues and eigenvectors of the covariance matrix
eigenvalues, eigenvectors = np.linalg.eigh(cov)
# Calculate the ellipse parameters
width = 2 * scaling_factor * np.sqrt(eigenvalues[1]) # Semi-major axis
height = 2 * scaling_factor * np.sqrt(eigenvalues[0]) # Semi-minor axis
angle = np.degrees(np.arctan2(eigenvectors[1, 1], eigenvectors[0, 1])) # Use the largest eigenvalue's eigenvector
# Return the ellipse
if plot:
return Ellipse(xy=mean, width=width, height=height, angle=angle, alpha=.2, color="#c44e52")
else:
return mean, width, height, angle
fig, ax = plt.subplots(figsize=(5, 5))
scat = ax.scatter(
spiral_data[0, 0],
spiral_data[0, 1],
edgecolor="k",
alpha=0.4,
s=10
)
scat2 = ax.scatter(
means[0, 1],
means[0, 0],
edgecolor="#c44e52",
s=25
)
plot = ax.plot(
means[0, 1],
means[0, 0],
color="#c44e52",
linestyle="--",
label="Belief trajectory"
)[0]
# Confidence intervals
ellipse = plot_confidence_intervals(means[0, :], covariances[0, :])
ax.add_patch(ellipse)
ax.grid(linestyle="--")
ax.set(
xlim=[-35, 35],
ylim=[-35, 35],
xlabel=r"$x_1$",
ylabel=r"$x_2$",
title=f"Bayesian Filtering \n of a Bivariate Stochastic Process",
)
plt.tight_layout()
def update(frame):
frame *= 3
# update the scatter plot
data = np.stack([spiral_data[:frame, 0], spiral_data[:frame, 1]]).T
scat.set_offsets(data)
data2 = np.stack([means[frame, 0], means[frame, 1]]).T
scat2.set_offsets(data2)
# update the belief trajectory
plot.set_ydata(means[:frame, 1])
plot.set_xdata(means[:frame, 0])
# update the confidence intervals
mean, width, height, angle = plot_confidence_intervals(
means[frame, :], covariances[frame, :], plot=False
)
ellipse.set_center(mean)
ellipse.width = width
ellipse.height = height
ellipse.angle = angle
return scat, scat2, plot, ellipse
ani = FuncAnimation(fig=fig, func=update, frames=333, interval=100)
ani.save("anim.gif")
Using a dynamically adapted \(\nu\) through a collection of Hierarchical Gaussian Filters#
Filtering the sufficient statistics of a two-dimensional multivariate normal distribution requires tracking the values of 5 parameters in parallel. Our model therefore consists of 5 independent two-level continuous HGF.
bivariate_hgf = Network().add_nodes(
kind="ef-state", learning="hgf-2", distribution="multivariate-normal", dimension=2
)
# adapting prior parameter values to the sufficient statistics
# covariances statistics will have greater variability and amplitudes
for node_idx in [2, 5, 8, 11, 14]:
bivariate_hgf.attributes[node_idx]["tonic_volatility"] = -2.0
for node_idx in [1, 4, 7, 10, 13]:
bivariate_hgf.attributes[node_idx]["precision"] = 0.01
for node_idx in [9, 12, 15]:
bivariate_hgf.attributes[node_idx]["mean"] = 10.0
bivariate_hgf.plot_network()

bivariate_hgf.input_data(input_data=spiral_data);
# get the sufficient statistics
xis = jnp.apply_along_axis(
MultivariateNormal().sufficient_statistics_from_observations,
1,
spiral_data,
)
System configuration#
%load_ext watermark
%watermark -n -u -v -iv -w -p pyhgf,jax,jaxlib
Last updated: Tue, 16 Jun 2026
Python implementation: CPython
Python version : 3.12.13
IPython version : 9.14.1
pyhgf : 0.3.0
jax : 0.4.31
jaxlib: 0.4.31
IPython : 9.14.1
jax : 0.4.31
matplotlib: 3.11.0
numpy : 2.4.6
pyhgf : 0.3.0
seaborn : 0.13.2
Watermark: 2.6.0