Planning and acting with predictive coding networks#
![]()
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import treescope
from jax import random
from jax.random import PRNGKey
from pyhgf import load_data
from pyhgf.model import Network
from pyhgf.utils.sample import sample
np.random.seed(123)
plt.rcParams["figure.constrained_layout.use"] = True
treescope.basic_interactive_setup(autovisualize_arrays=True)
This section concerns the application of predictive coding networks to planning and acting. While Bayesian filtering has been applied so far to the perceptual component of the agent, here we are interested in active inference and decision making, where an agent use its current beliefs to estimate future trajectories and select action based on there planned relevance.
Adding an action layer#
By adding a step in the belief propagation function, we can create agents that perform actions and interact with the environment (e.g., influencing the observation it might be presented). When provided, a new function, action_fn, can perform actions, decide, or influence the environment after the prediction step and before the observation step.
flowchart TB
A[Predictions] -- Action_fn --> B[Observation] --> C[Prediction-errors]
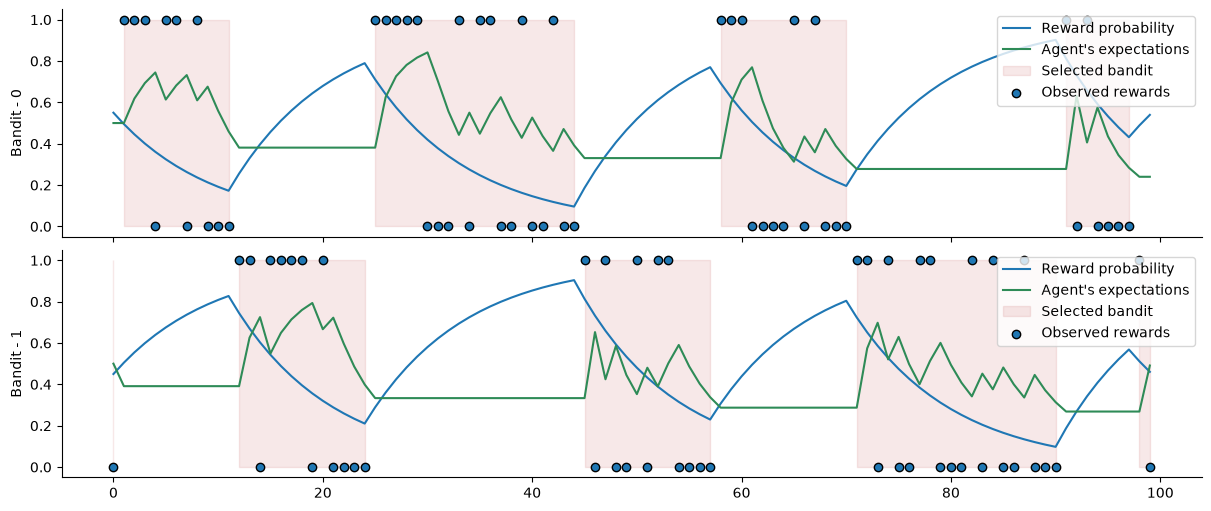
We illustrate how to implement this by using a two-bandit design, where the value of the contingencies increases or decreases depending on whether the bandit is exploited by the agent. An exploited bandit will decrease its contingency such as: \(c = c - (\lambda c)\), whereas a bandit that was not exploited will increase its contingency such as: \(c = c + \lambda * (1 - c)\). We, therefore, have to interact with the environment inside the inference loop. Luckily, we can do this by defining the corresponding action function.
# we start by defining a simple network with two binary branches
network = (
Network()
.add_nodes(kind="binary-state", n_nodes=2)
.add_nodes(value_children=0, tonic_volatility=-2.0)
.add_nodes(value_children=1, tonic_volatility=-2.0)
)
network.plot_network()

Here, we want to access information from the environment during inference, so we have to wrap this into the Network.attributes instance. By convention, all items indexed with positive integers are nodes from the network, and we should not interact with them. Negative integers can be used to index additional information. For example, the time steps are stored in attributes[-1]["time-steps"]. Here, we will simply store the contingencies of the two bandits inside the same branch.
network.attributes[-1]["contingencies"] = jnp.array([0.5, 0.5])
We then define the action function. This function should receive and return the attributes dictionary, and the inputs tuple. By modifying values in this variable, we can change the observed values before they enter the network.
def action_fn(attributes, inputs, node_idx):
"""Select the bandit with the highest expected reward."""
# unpack the inputs
values_tuple, observed_tuple, time_step, rng_key = inputs
# get the current expectation for a reward for both bandits
mu_0 = attributes[0]["expected_mean"]
mu_1 = attributes[1]["expected_mean"]
# sample a new reward from both bandits - the unobserved value will be masked later
# here simply use the highest expected value to select the bandit
values_tuple = (
jnp.int32(random.bernoulli(rng_key, p=attributes[-1]["contingencies"][0])),
jnp.int32(random.bernoulli(rng_key, p=attributes[-1]["contingencies"][1])),
)
observed_tuple = (jnp.int32(mu_0 - mu_1 > 0), jnp.int32(mu_0 - mu_1 <= 0))
# decrease value of the contingencies for the exploited bandit and increse the value of the non exploited one
exploited = attributes[-1]["contingencies"] - 0.1 * attributes[-1]["contingencies"]
non_exploited = attributes[-1]["contingencies"] + 0.1 * (
1.0 - attributes[-1]["contingencies"]
)
attributes[-1]["contingencies"] = jnp.where(
jnp.array(observed_tuple), exploited, non_exploited
)
# create a new input tuple
inputs = values_tuple, observed_tuple, time_step, rng_key
return attributes, inputs
We can now register this function as an action step in our Network class. The action_steps attribute takes a sequence of (node_idx, update_fn) tuples, so the action function will be called inside the belief propagation step, between prediction and observation.
network.action_steps = ((0, action_fn),)
We are now ready to run the model forward. Here, the input data only inform the number of time steps because we are fully overwriting the input values inside the action function, we could provide any kind of array of same shape and type as well.
# because there is a stochastic component in the reward, we need to pass a pseudorandom number generators
rng_key = random.PRNGKey(0)
network.input_data(input_data=np.ones((100, 2)), rng_keys=random.PRNGKey(0));
Predicting future belief trajectories#
While we have been mostly concerned with an agent’s direct observation of the environment, more realistic scenarios involve agents that actively predict possible outcomes to navigate their environment. Predictive neural networks are generative models tracking the latent causes of environmental observations. We can use this generative model to simulate new observations by sampling from the predictive distribution and passing them as new observations to an imaginary agent. In this section, we illustrate how to perform such a process which can give insight into expected future outcomes and serve as action selection for active inference.
# Define a three-level binary HGF and display the network
three_level_hgf = (
Network()
.add_nodes(kind="binary-state")
.add_nodes(value_children=0, tonic_volatility=-2.0)
.add_nodes(volatility_children=1, tonic_volatility=-2.0)
)
# Plot the network structure
three_level_hgf.plot_network()

Generative sampling (i.e. sampling an observation from the predictive distribution and passing it for update as actual observation) require a different belief propagation function to be defined beforehand to use the sampling methods. This can be achieved by explicitely passing sampling_fn=True when creating the main propagation functions:
# create the belief propagation functions, both for external and generative inputs
three_level_hgf.create_belief_propagation_fn(sampling_fn=True);
From here, we can already sample a set of plausible trajectories using the pyhgf.utils.sample() function. This function returns the attributes dictionary with a belief trajectory for each parameter/simulation. Here, we use the current state of the network and simulate plausible observations forward, and update the model accordingly - we therefore have 50 agents simulating forward in parallel.
Tip
You can unroll the nodes/parameters from the dictionary below for interactive visualisation.
# sample 50 possible trajectories looking 150 time steps into the future
sample_trajectories = sample(
network=three_level_hgf,
time_steps=np.ones(150),
rng_key=PRNGKey(4),
n_predictions=50,
)
sample_trajectories
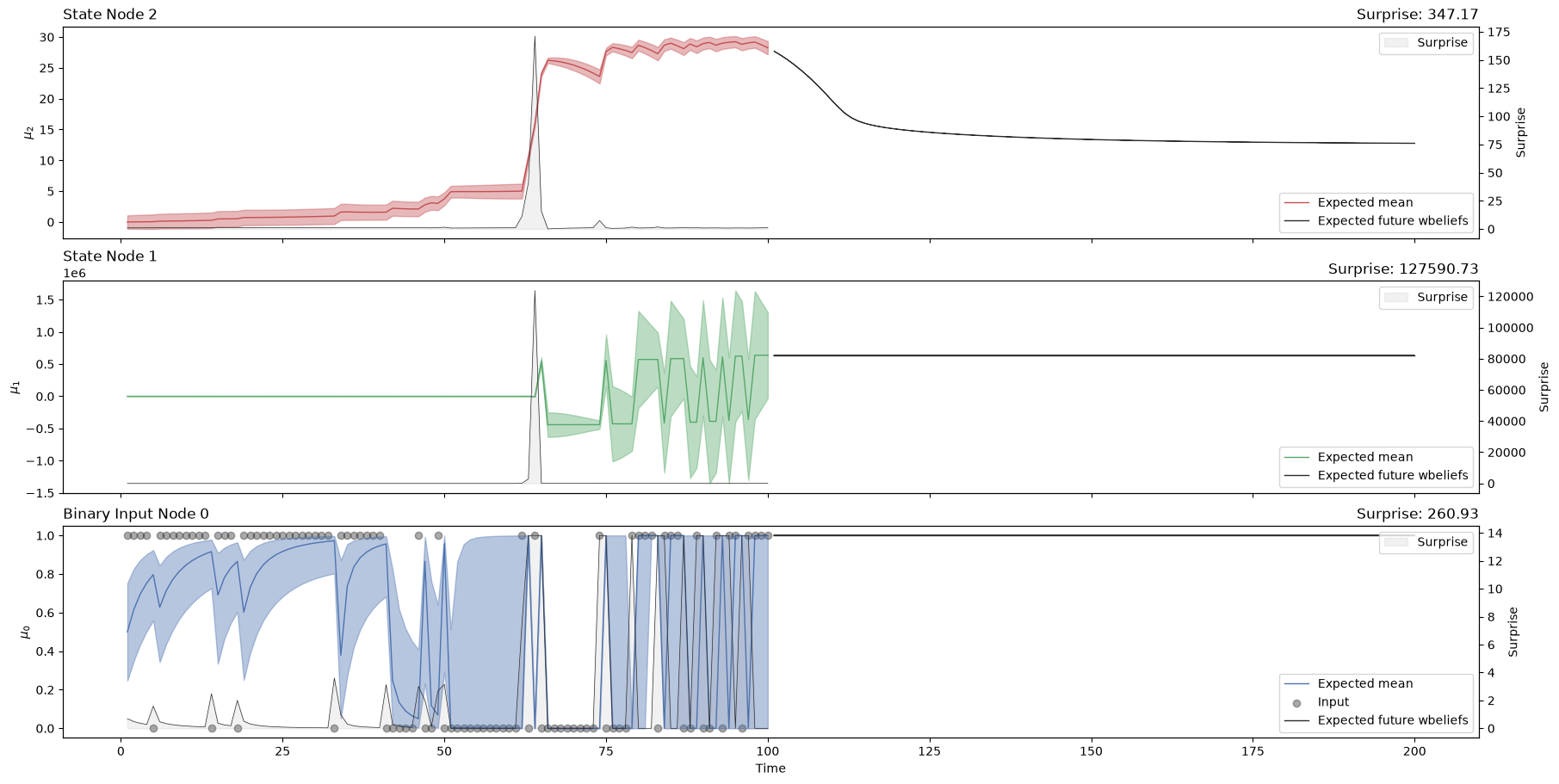
Alternatively, this simulation can take place after observing some data, in which case the last stat of the network is used and the simulation of plausible trajectories is just run forwards.
u, y = load_data("binary")
three_level_hgf.input_data(input_data=u[:100]);
# sample 50 possible trajectories looking 100 time steps into the future
three_level_hgf.sample(time_steps=np.ones(100), rng_key=PRNGKey(4), n_predictions=50);
# plot the belief trajectories (observed data)
axs = three_level_hgf.plot_trajectories()
# add the plausible simulation at the end of the time series to indicate future expectations
three_level_hgf.plot_samples(axs=axs);
/home/runner/work/pyhgf/pyhgf/.venv/lib/python3.12/site-packages/pandas/core/arraylike.py:402: RuntimeWarning: overflow encountered in exp
result = getattr(ufunc, method)(*inputs, **kwargs)
System configuration#
%load_ext watermark
%watermark -n -u -v -iv -w -p pyhgf,jax,jaxlib
Last updated: Tue, 16 Jun 2026
Python implementation: CPython
Python version : 3.12.13
IPython version : 9.14.1
pyhgf : 0.3.0
jax : 0.4.31
jaxlib: 0.4.31
IPython : 9.14.1
jax : 0.4.31
matplotlib: 3.11.0
numpy : 2.4.6
pyhgf : 0.3.0
seaborn : 0.13.2
treescope : 0.1.10
Watermark: 2.6.0